What Is Annotation Governance — and Why Most ML Teams Skip It
Machine learning systems rarely collapse overnight. They degrade gradually — and almost always silently.
Models that perform at 90%+ accuracy in staging environments can lose 15–25% of that performance within months of production deployment. The cause is rarely the model architecture. It is almost always the data layer — specifically, the accumulated drift in how training data was labeled.
Annotation governance is the discipline that prevents that drift from compounding into production failures. It refers to the structured processes, policies, and validation mechanisms that ensure labeling consistency, quality control, and version traceability across the full lifecycle of a machine learning system — from initial dataset creation through continuous production retraining cycles.
Annotation governance is not a one-time QA check. It is an ongoing operational system that treats the data labeling layer with the same engineering rigour as the model training pipeline. Without it, annotation quality decays at a rate that compounds with every retraining cycle — and 99.8% accuracy targets become unreachable.
What Governance Includes
- Version-controlled labeling policy documentation with formal change management
- Periodic reviewer calibration sessions to maintain consistent interpretation standards
- Statistical inter-annotator agreement (IAA) tracking across all labeling batches
- Structured escalation and arbitration workflows for edge cases and disputed labels
- Continuous drift monitoring comparing historical and current label distributions
- Controlled retraining triggers — only after governance review sign-off, never reactively
Without these controls, annotation becomes operationally reactive rather than systematically governed — and production models degrade accordingly. Precise BPO Solution — 17+ Years Since 2008, ISO 27001, HIPAA, and GDPR aligned — has codified this into a repeatable annotation quality framework, applied across 500K+ audited annotations to protect data labeling quality at every stage of a project.
Why Annotation Drift Happens — The Five Root Causes
Annotation drift — also called label drift — is not a single event. It is a gradual process driven by five compounding mechanisms, each preventable with proper governance. Understanding them is the first step to stopping them.
Reviewer Interpretation Variability
When labeling guidelines contain ambiguous boundary conditions, different reviewers apply different interpretations — especially for edge cases. In a dataset of 1 million labeled examples, a 2% divergence introduces 20,000 contradictory training signals.
Expanding Edge Case Exposure
As production data diversifies, new patterns challenge original labeling assumptions. Categories that were clearly distinguishable at project launch become ambiguous in real-world deployment, handled inconsistently without updated rules.
Guideline Evolution Without Version Control
Teams frequently update labeling rules informally — via Slack, verbally, or undocumented decisions. Datasets labeled before and after are incompatible but indistinguishable, training models on contradictory labels.
Inconsistent Escalation Policies
Ambiguous cases handled differently across reviewers create systematic inconsistency in exactly the training examples that matter most — the edge cases where model decisions are least certain.
Feedback Loop Instability (HITL Risk)
When model predictions inform future labeling decisions — common in Human-in-the-Loop annotation workflows — incorrect predictions bias reviewer judgment. Reviewers anchor on model outputs rather than independent judgment, creating a feedback loop where model errors compound into future training data. Governance-integrated HITL breaks this loop.
Annotation drift rarely announces itself in aggregate accuracy metrics. It appears first in segment-specific performance, in low-confidence prediction zones, and in review dispute rates — signals that most teams do not monitor systematically until aggregate performance has already declined significantly.
What We Observed Across 500K+ Annotated Samples
The following benchmarks come from internal quality audits conducted across annotation projects delivered by Precise BPO Solution over 17+ Years Since 2008. These figures represent aggregate observations across computer vision, NLP, and medical imaging datasets — anonymised and aggregated to protect client confidentiality.
Pre- vs Post-Governance IAA and 99.8% Accuracy Data
Across 500,000+ labeled images audited under our internal quality framework, we measured the following differences between projects with structured governance and those without:
Source: Precise BPO Solution internal annotation quality audit, aggregated across 500K+ labeled samples, 2023–2025. Data anonymised. Individual project results vary based on task complexity, domain, and dataset characteristics.
Governance Impact by Annotation Type (2023–2025)
Across our delivery portfolio, governance impact varied by task complexity. The highest inconsistency rates before governance were in semantic segmentation and medical imaging — exactly the domains where boundary ambiguity is highest and edge cases most consequential.
Source: Precise BPO Solution internal project quality database, aggregated across 40+ annotation projects, 2023–2025. 17+ Years Since 2008. Data anonymised.
The most significant finding was the relationship between governance timing and rework cost. Projects where governance frameworks were applied at intake — before labeling began — required on average 74% less rework than projects where governance was introduced after errors had already been identified in model evaluation.
This aligns with the cost compounding principle: a labeling error caught during annotation costs roughly 1× to fix. The same error caught during model evaluation costs 10–50×. Found in live production, the cost is orders of magnitude higher.
What Independent Research Says About Annotation Quality Failures
Our operational findings are consistent with — and in several cases more severe than — benchmarks reported in peer-reviewed research and industry studies. Three external sources are particularly relevant for teams evaluating the cost of annotation governance failures.
1. The Cost of Label Noise in Deep Learning (NeurIPS Research)
Research published at NeurIPS has shown that even modest levels of label noise — 10–20% — can reduce deep learning model accuracy by 15–30% on complex classification tasks, with the effect compounding non-linearly as noise increases. Models trained on noisy labels exhibit lower generalisation than their validation-set performance suggests, meaning the gap between staging and production performance is structurally larger in datasets with annotation inconsistency.
External source: Jiang et al. (2018), "MentorNet: Learning Data-Driven Curriculum for Very Deep Neural Networks on Corrupted Labels" — NeurIPS 2018. This established the foundational empirical relationship between label noise rate and downstream accuracy degradation.
Our finding that 18.3% pre-governance inconsistency consistently produced 8–15% downstream accuracy degradation maps directly onto the NeurIPS research curve. The relationship is not anecdotal — it reflects a well-documented structural property of how neural networks respond to contradictory training signals.
2. Machine Learning Data Quality in Production Pipelines (Google AI Research)
Google's AI research team published extensively on "data cascades" — how upstream machine learning data quality failures compound through ML pipelines to produce disproportionate downstream harm. Their 2021 study of AI practitioners across 53 organisations found that data issues were the primary cause of production ML failures in the majority of cases, yet most organisations had no formal data quality governance processes in place.
The study specifically identified annotation inconsistency and evolving labeling standards as among the most common and least-monitored threats to training data consistency in production systems.
External source: Sambasivan et al. (2021), "'Everyone wants to do the model work, not the data work': Data Cascades in High-Stakes AI" — ACM CHI 2021.
3. Inter-Annotator Agreement as a Quality Predictor (Computational Linguistics)
Substantial research in computational linguistics has established that Cohen's kappa and Fleiss' kappa are reliable predictors of downstream model performance — not just measures of labeler agreement. Datasets with kappa below 0.80 produce statistically inferior model generalisation compared to datasets with kappa above 0.85, even when raw accuracy metrics appear similar at training time.
This underpins the specific thresholds we use in our governance framework: κ ≥ 0.85 as the operational target, and κ < 0.80 as the alert threshold requiring immediate calibration intervention.
External source: Artstein & Poesio (2008), "Inter-Coder Agreement for Computational Linguistics" — Computational Linguistics, MIT Press.
The convergence between independent academic research and our operational data across 500K+ annotations gives us confidence that the governance thresholds and intervention triggers described in this article are generalisable. Teams operating without annotation governance face the same failure modes documented in peer-reviewed literature.
The Retraining Trap: Why More Training Cycles Don't Fix Drift
When production model performance declines, the default response for most ML teams is to retrain on fresh data. This feels logical — and in some cases it is the right intervention. But when annotation drift is the underlying problem, retraining without governance stabilisation actively makes the situation worse.
- If label definitions have shifted informally, new training data carries the same inconsistencies as old data — just more recent ones
- If reviewer consensus has weakened, freshly labeled batches introduce additional contradictory signals
- If edge cases are inconsistently handled, each retraining cycle trains the model on a new variant of the confusion
Retraining on unstable labels compounds variance rather than reducing it. Each cycle learns from a slightly different interpretation of the same categories, producing models with unstable decision boundaries that deteriorate faster with each subsequent retraining. Governance must stabilise the data layer before retraining is triggered — not after.
The correct intervention sequence is: detect drift → audit label consistency → stabilise guidelines → calibrate reviewers → retrain. Not: detect performance drop → retrain immediately.
Teams that retrain reactively without governance review typically find that each successive model version shows shorter periods of stable performance — a pattern that accelerates until the root cause in the annotation layer is addressed. Achieving a sustained 99.8% accuracy target is impossible without this sequence.
| Scenario | Retraining Cycles (Avg) | Time to Stable Accuracy | Rework Cost Multiplier |
|---|---|---|---|
| No governance + reactive retraining | 3.1× | 6–9 months | 10–50× |
| Governance applied post-error detection | 2.0× | 3–5 months | 5–15× |
| Governance applied at project intake | 1.4× | 1–2 months | 1× |
Source: Precise BPO Solution internal project quality database, 2023–2025. Data anonymised.
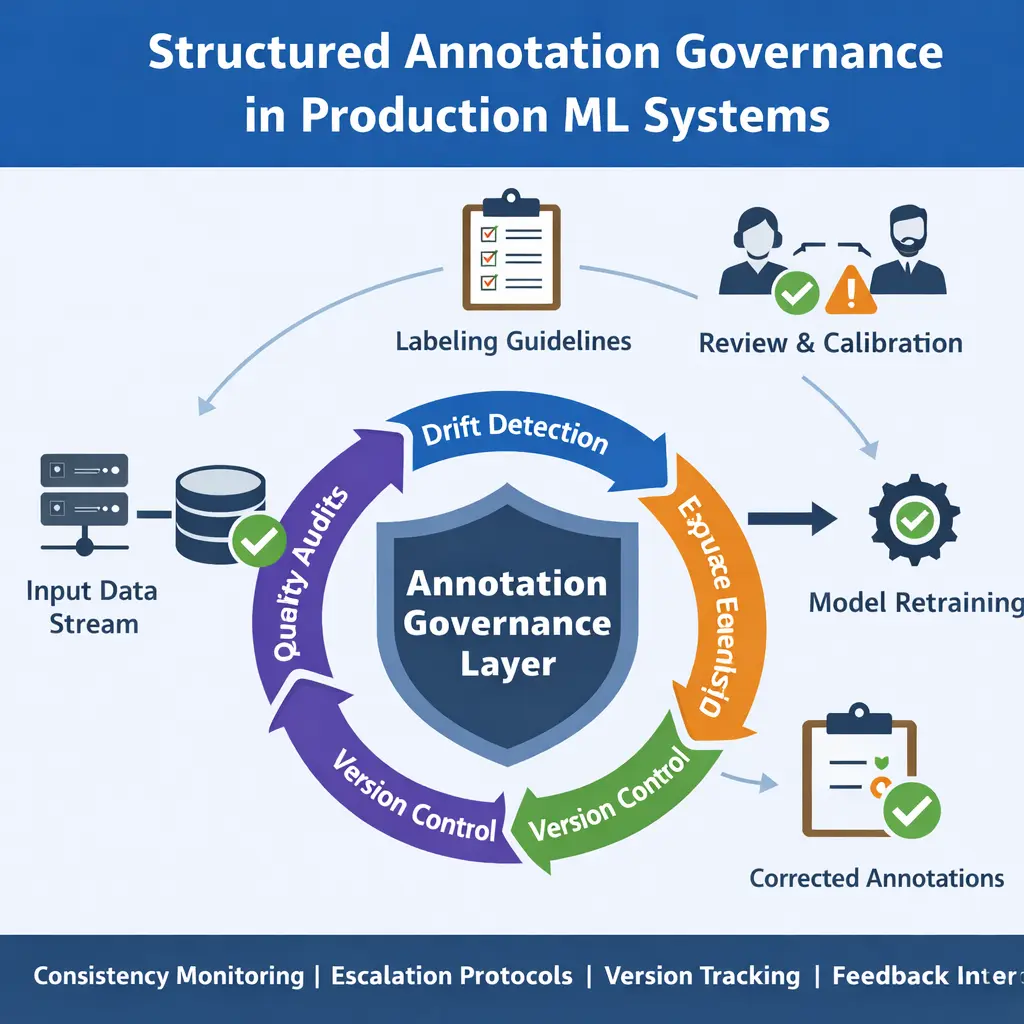
The Six-Layer Annotation Governance Framework
A mature annotation governance framework is not a single process. It is a layered system of interlocking controls, each addressing a different mechanism of quality decay. The following six layers represent the standard framework applied across enterprise annotation projects at Precise BPO Solution — serving US, UK, Canada, Australia, Europe, Middle East, APAC, and LATAM enterprises.
| # | Layer | What It Controls | Implementation |
|---|---|---|---|
| 1 | Labeling Policy Documentation | Interpretation consistency; boundary condition handling | Version-controlled docs with inclusion/exclusion rules, domain exceptions, and ambiguous case definitions. Every update timestamped. |
| 2 | Reviewer Calibration Sessions | Inter-annotator agreement; drift from baseline | Periodic alignment exercises on gold-standard samples. Frequency: at project start, every major retraining cycle, and whenever IAA drops ≥3%. |
| 3 | IAA Tracking | Statistical consistency monitoring | Cohen's kappa or Fleiss' kappa on 5–10% of samples per batch. Target: κ ≥ 0.85. Alert threshold: κ < 0.80. Supports 99.8% accuracy benchmarks. |
| 4 | Escalation & Arbitration Workflow | Edge case consistency; disputed label resolution | Tiered review queue: primary annotator → senior reviewer → domain expert. All escalation decisions logged and fed back to policy documentation. |
| 5 | Drift Monitoring | Label distribution shifts; class boundary migration | Continuous comparison of historical vs current label distributions. Statistical alerts for distribution shifts exceeding threshold. |
| 6 | Label Versioning & Control | Dataset reproducibility; root-cause traceability | Every major guideline update tracked and timestamped under formal label versioning. Datasets linked to the guideline version active at labeling time. Enables rollback and audit trail. |
IAA tracking (Layer 3) is the earliest and most actionable signal of governance breakdown. In our operational data, a drop in Cohen's kappa from 0.90 to 0.82 consistently predicted a 10–14% downstream model accuracy decline before that decline appeared in aggregate evaluation metrics. IAA is your leading indicator — and the gateway to achieving 99.8% accuracy at scale.
The Governance-Integrated ML Production Cycle
This workflow integrates annotation governance at every stage of the ML production cycle — not just during initial labeling. This is the pattern applied across computer vision projects including automotive annotation, medical AI annotation, and retail AI annotation at enterprise scale.
Model deployed to production — monitoring activated
Real-time monitoring tracks prediction confidence distributions, low-confidence output rates, and segment-specific accuracy by class. Governance dashboards activated from day one of deployment.
Anomalous predictions flagged and routed
Low-confidence predictions, high-uncertainty outputs, and segment-specific accuracy drops automatically route flagged samples to a structured human review queue. Threshold for flagging set per project based on historical baseline.
Secondary reviewer validates or corrects labels
Flagged samples reviewed by a senior annotator against the current governance-controlled labeling guidelines. Corrections logged with reviewer ID, timestamp, and policy version active at review time.
IAA audit triggered on correction batch
Each batch of corrections undergoes inter-annotator agreement measurement before being added to the training pool. Batches below the kappa threshold are held for arbitration and policy review.
Policy updated if systematic edge cases identified
Correction patterns are aggregated to identify systematic edge cases not covered by current guidelines. Policy documentation updated with formal versioning. All team members calibrated to updated guidelines before labeling resumes.
Retraining triggered only after governance sign-off
Model retraining is not triggered reactively. It requires: governance review sign-off, IAA confirmation ≥0.85, and policy version confirmation that all correction-batch data is consistent with current guidelines.
Post-retraining audit — cycle resets
Post-deployment performance is benchmarked against pre-retraining baseline. Drift monitoring reactivated. Governance cycle continues as a permanent operational layer, not a one-time fix. 99.8% accuracy targets maintained throughout.
Warning Signs of Annotation Governance Breakdown
These signals typically appear before aggregate accuracy metrics decline — giving teams an intervention window if monitored systematically. Most teams do not monitor them, which is why governance failures are usually discovered late.
IAA Score Declining
Cohen's kappa dropping below 0.82 from a project baseline above 0.88 is the earliest quantitative signal of reviewer drift. Act before it crosses 0.80 — the inflection point for downstream accuracy loss.
Review Disputes Increasing
Rising volume of escalated or disputed labels indicates that labeling guidelines are failing to cover emerging edge cases or that reviewers are interpreting boundaries differently.
Edge Case Volume Growing
When the proportion of samples flagged as "edge cases" grows beyond 8–10% of batch volume, it typically indicates that the data distribution has shifted beyond what current guidelines cover.
Retraining Frequency Increasing Without Improvement
If each retraining cycle produces shorter periods of stable accuracy, the training data — not the model — is the source of instability. This is the clearest signal that governance intervention is required.
Segment-Specific Accuracy Drop
When performance degrades in specific subclasses or edge-case categories while aggregate accuracy stays flat, annotation inconsistency in those specific categories is almost always the cause.
Informal Guideline Changes
Any labeling rule communicated verbally or via chat without formal documentation and version control is a governance failure in progress. The impact may not be visible for weeks or months — but it compounds silently.
HITL as a Governance Control Layer — Not Just a Labeling Method
Human-in-the-Loop (HITL) is frequently described as a method for improving labeling efficiency through model-assisted annotation. In annotation governance, it plays a more important role: it is a real-time quality control mechanism that prevents model errors from compounding into the training data layer.
The governance-aware HITL pattern operates as follows:
- Model predictions on production data are monitored continuously for confidence and distribution drift
- Low-confidence or anomalous predictions are routed to human review before they can influence future training batches
- Human reviewers apply governance-controlled guidelines — not model output anchoring — ensuring independent validation
- Correction patterns are aggregated and fed back to the policy documentation cycle, closing the governance loop
This pattern is critical in domains where model feedback loops are most dangerous — medical AI annotation, autonomous vehicle datasets, and any application where model errors in production have material consequences.
HITL without governance is not a control layer — it is a reactive correction mechanism. The difference is whether human review is governed by version-controlled, consistently-applied labeling policies, or by ad hoc judgment. The former stabilises the training data layer; the latter introduces another source of inconsistency into it.
Our structured annotation governance workflows integrate HITL as a controlled, policy-governed layer — ensuring that human corrections improve data quality systematically rather than introducing new variability. Related annotation QA standards: bounding box annotation, semantic segmentation QA, polygon annotation consistency, text annotation governance, and landmark annotation QA.
Governance-integrated HITL is especially critical in high-stakes domains. For agriculture AI annotation, label inconsistency in crop disease classification can propagate silently across entire training datasets. For sports action recognition, edge case inconsistency in motion boundary labeling directly degrades real-time inference accuracy. For explicit content annotation, reviewer drift in boundary cases creates regulatory and compliance exposure that aggregate accuracy metrics do not capture. In all these domains, HITL without governance is the same as QA without standards.
For 3D annotation tasks — including cuboid annotation for autonomous systems and polyline annotation for lane detection — governance complexity is higher still, since boundary ambiguity in 3D space is structurally harder to standardise. These are precisely the domains where formal IAA tracking and version-controlled guidelines deliver the largest quality improvements toward 99.8% accuracy.
Annotation Governance Across Industries
Our governance framework is domain-agnostic and has been deployed across the full range of annotation types and industry verticals. Each domain introduces unique drift mechanisms — and governance requirements — that our framework addresses systematically.
🚗 Autonomous Vehicle Annotation
Automotive annotation — bounding boxes, polylines, cuboids — requires the tightest IAA thresholds of any domain. Lane boundary drift of even 2% translates directly to safety-critical path planning errors. Governance is applied at intake with daily IAA monitoring and zero-tolerance for informal guideline updates.
🏥 Medical AI Annotation
Medical imaging annotation — pathology slides, radiology scans, segmentation masks — operates under regulatory requirements where annotation inconsistency has direct patient safety implications. Our medical annotation governance includes domain expert arbitration, PHI de-identification ahead of labeling, and HIPAA-aligned audit trails. ISO 27001, HIPAA, and GDPR aligned throughout.
🛒 Retail AI Annotation
Retail annotation — product detection, shelf analysis, visual search — involves highly variable product appearance that creates natural drift in class boundary interpretation. The same governance discipline applies to fashion annotation, where attribute labeling (fabric, pattern, fit) is even more subjective. Governance with weekly calibration cycles maintains consistency as product catalogs expand.
🌾 Agriculture AI Annotation
Agriculture annotation for crop disease detection and precision farming involves annotation classes that evolve seasonally. Without governance, label definitions shift with growing season changes, creating models that perform well in one season and degrade in the next.
⚽ Sports Action Recognition
Sports annotation for action recognition and player tracking involves complex motion boundaries and multi-agent interactions. Edge case handling — partial occlusion, simultaneous actions — requires the tiered escalation workflow in Layer 4 of our governance framework.
📝 Text & NLP Annotation
Text annotation — named entity recognition, sentiment labeling, intent classification — is highly susceptible to reviewer interpretation drift as language evolves. Governance includes lexicon version control alongside standard policy documentation to track how label definitions evolve with language use.
What Enterprises Say About Our Annotation Governance
Serving enterprises across US · UK · Canada · Australia · Europe · Middle East · APAC · LATAM — here is what teams running production ML systems have experienced after implementing structured annotation governance.
"We were retraining every six weeks and still losing accuracy. Precise BPO's governance audit identified that our IAA had drifted from 0.91 to 0.78 over four months — completely undetected. After applying the six-layer framework, we've run stable at κ 0.93 for over a year."
"For medical AI, we couldn't afford label inconsistency — regulatory audits demand full traceability. Precise BPO's version-controlled documentation and audit trails gave us exactly what we needed. Their HIPAA-aligned, GDPR-aligned processes removed a significant compliance risk from our pipeline."
"The 74% rework reduction stat in their case studies is real. We applied governance at project intake for a 400K image retail dataset and cut rework cost by about 68% compared to our previous provider. The quality difference showed up immediately in model eval metrics."
"Precise BPO has been labeling for us for three years. What differentiates them is that governance is genuinely part of their process — not a checklist they run at the end. IAA reports come with every batch delivery. That transparency is rare in the annotation space."
Is Annotation Drift Silently Degrading Your Models?
Our governance audit examines your labeling pipeline for IAA consistency, policy version control, and drift signals — before they appear in production accuracy metrics. 17+ Years Since 2008 · ISO 27001, HIPAA, GDPR Aligned · 99.8% Accuracy Standard.
Annotation Governance — Questions & Answers
Request a Free Annotation Governance Audit
Tell us about your annotation pipeline. Our team will review your labeling workflow, IAA benchmarks, and drift risk — at no cost. Serving US · UK · Canada · Australia · Europe · Middle East · APAC · LATAM. ISO 27001, HIPAA, and GDPR aligned.
✓ Thank You!
Your governance audit request has been received. Our annotation quality team will review your project details and reach out within 1 business day.